Acoustic Scene Analysis
Source Localization
Acoustic source localization aims at extracting the localization information of one or several sound sources from signals captured by a number of spatially distinct microphones, as, e.g., depicted in Figure 1. By exploiting the spatial diversity, acoustic source localization techniques allow to estimate the position of one or several sound sources in a two-dimensional plane or in a three-dimensional space without any prior knowledge about the observed acoustical scene. This information can serve in many applications, e.g., humanoid robots or mobile phones, as a preliminary step to other processes like, e.g., steering a beamformer or tracking. Furthermore, it is a prerequisite for intuitive human-robot interaction.

Figure 1: Microphone array mounted on humanoid robot NAO
A wide variety of algorithms exist, each addressing different applications depending on the microphone configuration, e.g., single array or sensor network, static vs. mobile array, the source characteristics, e.g., broadband or narrowband, stationary or non-stationary, and the room characteristics, e.g., reverberation and background noise. In general, two different approaches can be identified, the direct approach and the time difference of arrival (TDOA) based approach.
Direct Approach
In the direct approach, the position of the active sound source(s) is characterized by an acoustical energy map of the search space. Depending on the localization task, the search space can be a discrete set of grid points in a plane or in a 3D space. It can also be a discrete set of directions, when the range from the sources to the sensors is disregarded. The latter case is usually referred to as the far-field search (i.e., for sources located far away from the sensors), in contrast to the near-field search.
TDOA-based approach
Approaches based on the TDOA rely on a two-step procedure. First one or several time delays between different pairs of microphones are estimated. Each TDOA corresponds to a hyperbolic set of possible source positions. Thus, by optimally intersecting the sets, the localization information can be extracted in a second step.
The research focus of the chair is summarized below.
Acoustic Sensor Networks
Acoustic Sensor Networks consist of sensor nodes, i.e., electronic devices, each equipped with one or several microphones. These nodes are spread over the area of interest and provide different point of views of the acoustic scene. This can be used for localization by fusion of the obtained spatial estimates of the single sensor nodes.
Localization exploiting MIMO Blind System Identification
Localization based on Blind System Identification (BSI) focuses on the estimation of the impulse responses between the sources and the microphones. It can be applied for a single source using the Adaptive Eigenvalue Decomposition (AED) algorithm [Benesty 2000], which performs Single-Input-Multiple-Output (SIMO) BSI. Contrary to the simpler synchrony-based methods, the AED explicitly accounts for the room reverberation in its signal model. It can be therefore expected to be more robust against reverberation. A generalization of the AED to perform Multiple-Input-Multiple-Output (MIMO) BSI has been developed at the Telecommunications Laboratory of the University of Erlangen-Nuremberg. It allows the localization of multiple sources and exploits an information-theoretic criterion based on BSS.
Active Localization
Most of the previous research has been focused on static arrays. With the increasing amount of humanoid robots in daily life a new degree freedom, the mobility of the array, is available. This leads to the question how it can be exploited, e.g., how to plan a suitable path to enhance the localization results. Path planning can be used to fight several problems, e.g., front-back confusion and mechanical steering. Additionally, it enables to create a 3 dimensional probabilistic source activity map, despite only measuring DoAs, e.g., far-field approach. Figure 2 depicts several snapshots of a mobile robot tracking an acoustic source. The belief about the source position is encoded by a set of weighted particles.
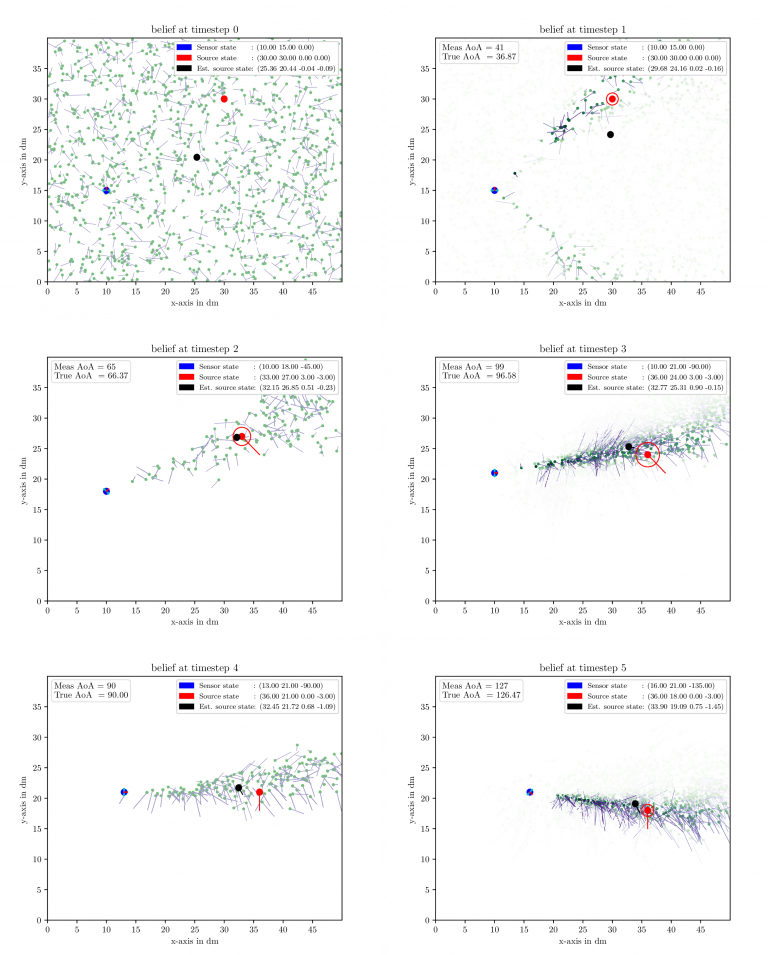
Figure 2: Active localization of an acoustic source
Estimation of room acoustic parameters
Estimation of Reverberation Time
The Reverberation Time (RT) or T60, which is defined as the time span in which the energy of a steady-state sound field decays by 60 dB below its initial level after switching off the excitation source, is an important and well-known measure to describe the acoustical properties of a reverberant enclosure. Furthermore, knowledge about the RT can be exploited to enhance the performance of Automatic Speech Recognition (ASR) systems as well as speech dereverberation. For such applications, the possibly time-varying RT can usually not be determined from a known room impulse response, but has to be estimated blindly from a reverberant speech signal, which is frequently also distorted by noise.
Estimation of Coherent-to-Diffuse Power Ratio
If multiple microphones are available, extraction of spatial information on the sound field, i.e., the spatial coherence between microphones, is possible. This spatial information can be used to estimate the Coherent-to-Diffuse Ratio, which is the power ratio between direct and diffuse (reverberation) signal components at the microphones, i.e., a measure for the amount of reverberation of an observed signal. Estimating the CDR requires an estimate of the spatial coherence between the microphones and the spatial coherence of the late reverberation component, which is assumed to be spherically diffuse. In addition, it is also possible to incorporate the DOA of the desired signal into the CDR estimate.
Non-linear system identification
The term system identification refers to the discipline of building mathematical models of dynamic systems from observed input-output data. This general term can be specialized into linear and nonlinear system identification depending on the characteristics of the model under consideration.
Due to its wide range of applications, nonlinear system identification has received an increasing interest from both researchers and practitioners. The applications include and are not limited to: nonlinear acoustic echo cancellation, tracking, and neural network parameterization. While a large number of approaches exist to address the problem of nonlinear system identification, research at the LMS focuses on the use of sequential Monte-Carlo-based estimators, i.e., particle filters.
Inference using particle filters is carried out by means of numerical sampling. They are deemed attractive due to their flexibility and capability of working with complex models without forcing any strong assumptions. This resulted in the development of the Elitist Particle Filter based on Evolutionary Strategies (EPFES), an approach that can be regarded as a hybrid combination of generic particle filters. The EPFES introduces a long-term memory to a group of particles, i.e., elitist particles, through an evolutionary resampling scheme. Benchmarked by several applications, e.g., nonlinear acoustic echo cancellation or single and multi-target tracking, the EPFES has been shown to outperform other generic particle filters, especially for the case of using a small number of particles.
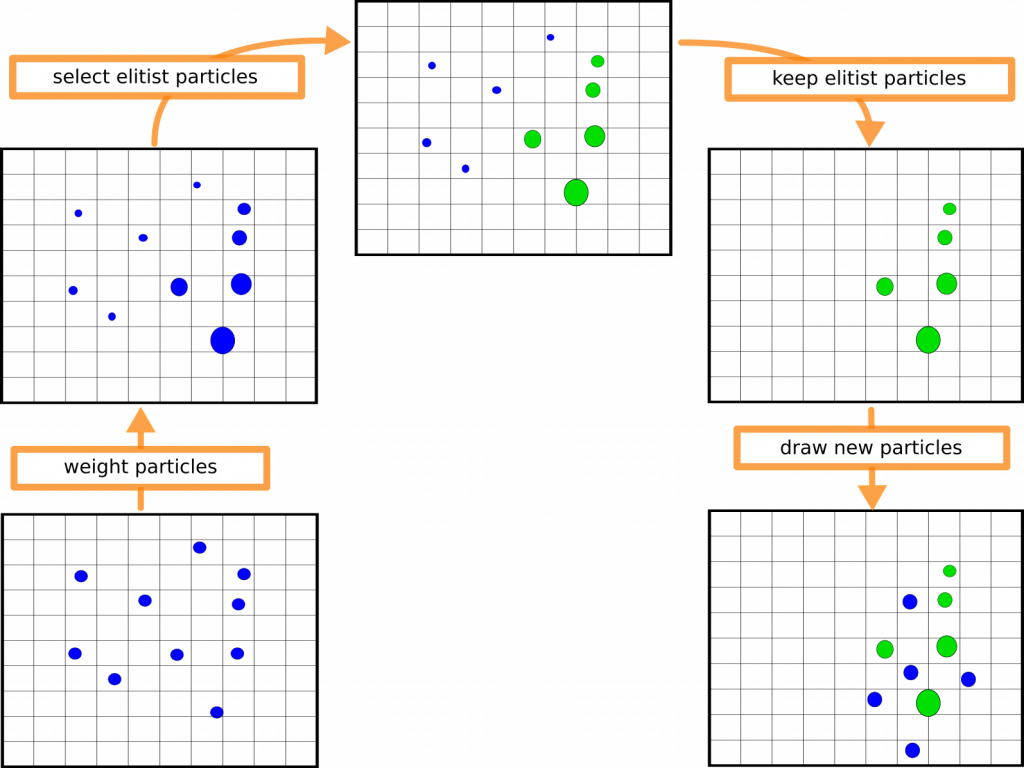
Evolutionary resampling in a two-dimensional state space
Source activity estimation
The knowledge about the activity of local sound sources in the recorded microphone signals is useful or required for many algorithms in acoustic signal processing. This side information can be employed to control adaptive algorithms, e.g., for source separation, or speech enhancement algorithms, e.g., noise reduction algorithms. In order to provide this information, the LMS pursuits two approaches at the development of source activity estimation algorithms.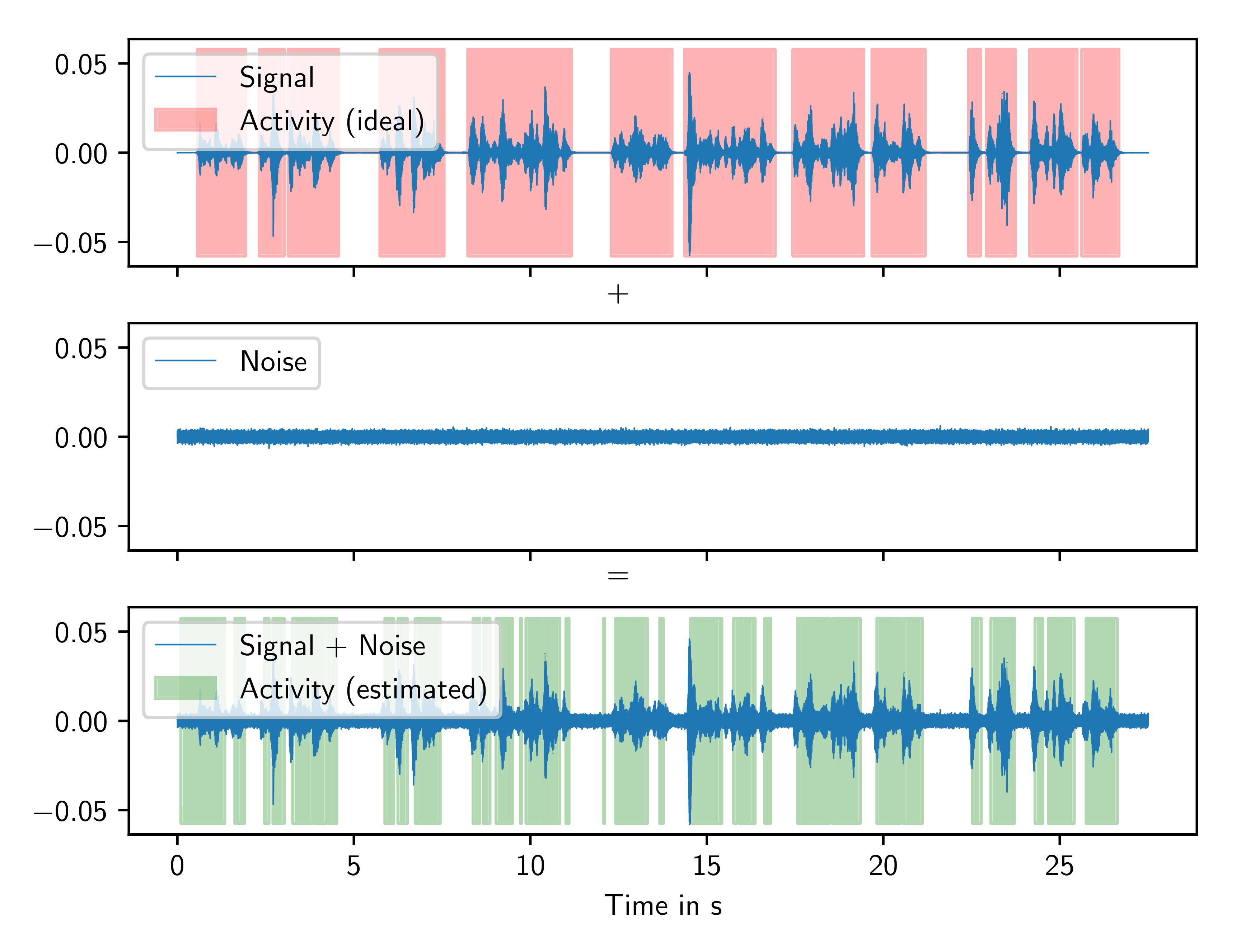
The first one relies on statistical modelling of all possible speakers by pretrained source models based on Student-t mixtures. Here, the algorithm estimates the contributions of all modeled sources to the observable convolutive mixture on the basis of a single-channel recording without source separation or dereverberation.
The second approach uses a microphone array to detect the activity of a target source at a known position. Spatial features like, e.g., crosscorrelation, SNR estimates, and coherence can be combined with conventional single-channel features for speech presence probability and the knowledge of the target source position. A deep neural network maps the resulting feature vector to a decision for target source activity, which can be made binarily or continuously. Alternatively, the network can be utilized to directly control parameters, like, e.g., the step size of a subsequent filter.