Acoustic Human-Machine Interfaces
Beamforming with Microphone Arrays
Beamforming with microphone arrays is typically used for extracting a desired signal without distortion while suppressing unwanted interference signals, if desired source and interferers are located at different spatial positions.
Broadband data-independent beamforming designs aiming at constant beamwidth usually lead to superdirective beamformers for low frequencies if the microphone spacing is small relative to the wavelengths. Superdirective beamforming is often desirable due to its inherent ability to provide high directional gain with a small array aperture satisfying constraints on space. However, these beamforming designs are highly sensitive to microphone self-noise, mismatch between microphone characteristics, and position errors. This may necessitate the use of expensive hardware such as matched microphones, high-precision microphone placement, and acquisition hardware with very low self-noise, which contradicts the desire for low-cost hardware, especially for off-the-shelf products. Therefore, broadband beamforming methods have to be developed that allow to directly control the robustness of the resulting design for given array hardware precision. To this end, research activities at the chair are focused on developing flexible design procedures that allow the robustness of the resulting beamformers to be adapted to given prior knowledge on microphone mismatch, positioning errors, and microphone self-noise. This resulted in the development of data-independent least squares beamforming approaches, which use a predefined white noise gain (WNG) constraint value to directly control the robustness of resulting beamformers.
The beamforming designs are optimum in the least squares sense and simultaneously constrain the WNG to remain above a given lower limit by directly solving constrained convex optimization problems. Well-established tools for specifying and solving convex problems may then be used to solve these problems. The major advantages of these designs are that they are applicable to arbitrary array geometries, i.e., there are no restrictions on microphone placement and they guarantee the optimal solution for a given array geometry, desired response, and chosen constraints. The capability of controlling the robustness of the resulting beamformer according to the user’s requirements underlines the flexibility of these design procedures.
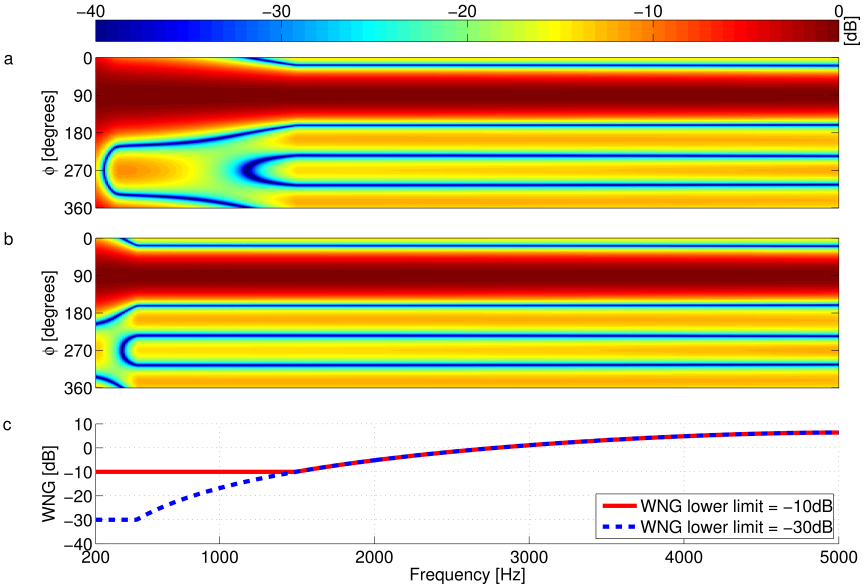
An exemplary design for a uniform circular array is shown in Figure 1: Exemplary robustness control of a beamformer design for a 6-element uniform circular array; Beampatterns for WNG lower limits of a) -10dB and b) -30; c) WNGs.
The beamforming designs described above are usually based on the free-field assumption of acoustic wave propagation. However, for scenarios where the microphones are mounted to a scatterer, the free-field assumption is not fulfilled, since the influence of the scatterer on the sound field is neglected, which will decrease the beamformer’s signal enhancement performance. One example of such a scenario is a microphone array mounted on a humanoid robot’s head used for robot audition (see Figure 2: Newly developed head for the NAO robot incorporating 12 microphones. Red dots highlight the microphone positions.). To overcome this limitation, Head-Related Transfer Functions (HRTFs) can be incorporated into the beamformer design instead of the free-field steering vectors. The resulting HRTF-based superdirective beamformer design then incorporates the influence of the scatterer on the sound field. Therefore, it yields a significantly increased signal enhancement performance compared to the original free field-based design.

Dereverberation
Later reverberation, caused by the reflecting surfaces in a room, leads to major degradation of recognition scores in automatic speech recognition. Thus, dereverberation, i.e., the suppression of the late reverberation components from the recorded microphone signal is an active field of research in the area of acoustical signal processing. In this field, LMS focuses on two dereverberation approaches which will be presented in the following: a) Blind Source Separation (BSS)-based dereverberation and b) coherence-based dereverberation.
The idea of BSS-based dereverberation is to first employ a BSS-based blocking matrix which is adapted to suppress the direct path and the early reflections of the desired signal, and thus directly generate an estimate of the late reverberation component in the blocking matrix output. This late reverberation estimate is used to compute a postfilter for spectral enhancement, e.g., a Wiener filter, which is then applied to the reverberant input signal.
In the case of coherence-based dereverberation, instead of directly producing an estimate of the late reverberation component as for the BSS-based approach, we estimate the Coherent-to-Diffuse Power Ratio (CDR), which is the power ratio between direct and diffuse (reverberation) signal components at the microphones. Assuming that, for example, weak diffuse signal components are present at the input of the system, the CDR in the corresponding time-frequency bin will exhibit high values. Estimating the CDR requires an estimate of the spatial coherence between the microphones and the spatial coherence of the late reverberation component, which is assumed to be spherically diffuse. In addition, it is also possible to incorporate the DOA of the desired signal into the CDR estimate. An example of the estimated diffuseness, which can be calculated from the CDR as 1/(1-CDR), is illustrated in Figure 1. It can be seen that when the target signal is active, i.e., strong direct-sound signal components are present at the microphones, the diffuseness exhibits low values, which corresponds to a large estimated CDR.
Similar to the BSS-based approach, the estimated CDR is then used to calculate spectral enhancement weights, e.g., using a single-channel Wiener filter, which are then applied to the microphone signal in the spectral domain in order to dereverberate the target signal.
Blind Source Separation
In a cocktail party scenario, many acoustic sources are active simultaneously. Thus, microphones which record the acoustic scene from a distance capture a mixture of all active sources. Since the individual source signals are of interest in many applications, it is desirable to recover them from the acoustic mixture. Blind Source Separation (BSS) algorithms rely on the assumption of mutually statistically independent source signals, which is generally justified for signals originating from different physical sources. In this context, ‘blind’ means that no other prior knowledge, e.g., of the acoustic scene or the microphone array geometry, is employed.
The TRIple-N Independent component analysis for CONvolutive mixtures (TRINICON) framework conceived at the LMS separates acoustic sources by simultaneous exploitation of the three fundamental signal properties of speech, namely non-Gaussianity, non-whiteness, and non-stationarity. Besides the original task of source separation, this generic and powerful concept is also suitable for the estimation of relative transfer functions. Several extensions incorporating prior knowledge have been developed and extend the applicability of TRINICON to problems such as simultaneous localization of multiple sources and signal extraction in overdetermined acoustic scenarios. Using the latter to separate one desired source from all others, up-to-date noise reference signals can be obtained, even if the number of sources exceeds the number of sensors. Such reference signals can then be employed, e.g., in a Generalized Sidelobe Canceller (GSC) structure.
Ego-Noise Suppression for Robot Audition
A robot’s capability to capture, analyze and react to its acoustic environment is referred to as robot audition. In this context, the robot caused self-noise by motors and motion is of crucial importance since it degrades the recorded audio signals of a microphone-equipped robot massively. Thereby, the robot’s auditory capabilities suffer. To relieve this problem, a suitable noise reduction mechanism is required. This task is particularly challenging because the noise involved is often louder than the signals of interest. Beside this, it is highly non-stationary as the robot performs different movements with varying speeds and accelerations. Furthermore, ego-noise cannot be modeled as a single static point interferer as the joints are located all over the body of the robot. However, it exhibits pronounced structures in the time-frequency domain. An intuitive approach for ego-noise suppression is therefore to learn those noise structures, collect them in a so-called dictionary and use its entries in the suppression step for a sparse representation of the current ego-noise sample. If multiple channels are considered, also instantaneous phases of all involved signal can be optimized account which outperforms single-channel approaches for ego-noise suppression.
In this context, motor data, i.e., the physical state of robot joint in terms of angle, angle speed and angle acceleration, can be useful for ego-noise suppression since it provides additional information about the joints of the robot and thereby the noise sources.