Particle Filtering for Data Augmentation in Image Classification

We congratulate Prof. Belagiannis and Alexander Tsaregorodtsev for their journal publication entitled “ParticleAugment: Sampling-based data augmentation“. Data Augmentation (DA) is employed during the training process of neural networks in order to prevent overfitting on the training data as well as ensure better generalization capabilities of the resulting network. While data augmentation policies can be hand-chosen for each network and training procedure, recently, automated data augmentation methods emerged. Automatic augmentation approaches try to find optimal augmentation policies which maximize the network performance of the currently trained network and eliminate the need to manually search for optimal augmentation hyper-parameters. Algorithms like AutoAugment use recurrent network controllers to generate augmentation policies, which are then benchmarked by training the target network. By applying a reinforcement learning scheme, the controller is taught to generate optimal policies. Other automatic approaches adapt policies using evolution algorithms (Population-Based Augmentation) or just randomly sample augmentations (RandAugment).
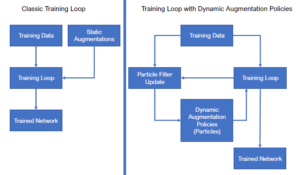
We developed a new automatic augmentation approach called ParticleAugment (PA). PA is based on the idea of paricle filters applied to neural networks. By representing the optimal augmentation policies as a probability distribution of variable-length policies, we can use a set of particles to approximate the yet unknown optimal distribution. During training, noise is applied to the particles, which are then evaluated by a chosen loss metric in order to adjust the particle weights and optimize the discrete policy distribution. Outside of the particle filter update step, the discrete distribution is used to sample policies from during the regular training steps. By alternating between network training and particle filter updates, the augmentation policies are adapted during training to improve the performance yields over the entire training procedure. Using our approach, we improve the final network performance while reducing the computational overhead required to find optimal augmentation policies.