Deep Learning-Based Video Coding for Machines
Description
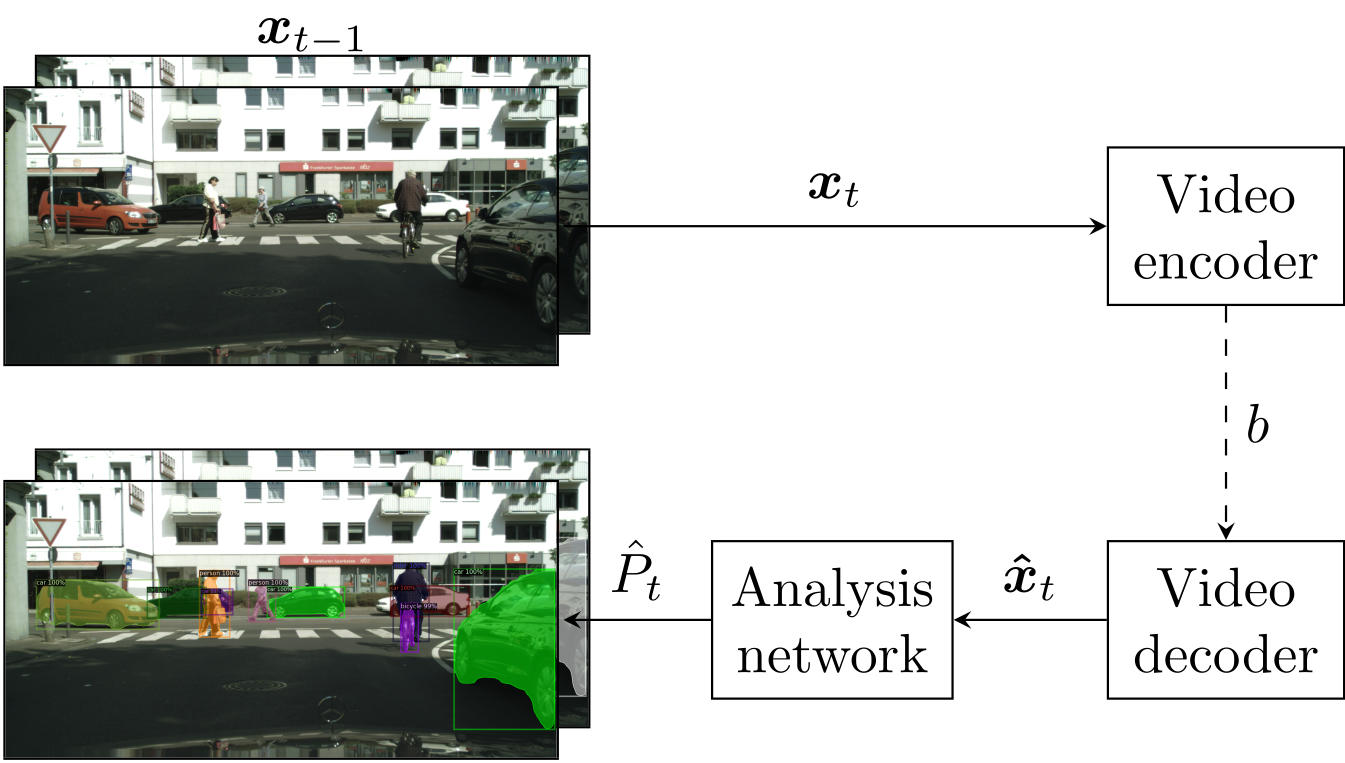
Increasingly, image and video data are not only evaluated by a human viewer, but instead by machines using algorithms. In many scenarios, such as smart city systems, the computing power at the recording device is too low to perform the evaluation locally. Instead, the image data is transmitted to devices with sufficient computing power. Since bandwidth is limited, lossy compression techniques must be applied. However, existing video compression techniques are optimized for visual reconstruction quality and not for optimal analysis with algorithms. In the context of “Video Coding for Machines” (VCM) different methods for this use case are investigated.
Prerequisites
Experience in programming with Python, Deep Learning (PyTorch/TF) and image and video compression is required.
Before applying, please check whether you have sufficient prior knowledge (esp. for research internships/master thesis) in the mentioned areas!
Supervisor
Marc Windsheimer
marc.windsheimer@fau.de
room 06.036
Professor
Prof. Dr.-Ing. André Kaup
andre.kaup@fau.de
room 06.031